移动推荐算法是阿里天池赛2015年赛题之一,题目以移动电商平台的真实用户-商品行为数据为基础来构建商品推荐模型。该题现已成为新人入门的经典演练对象,博主也希望基于该题场景,加深对机器学习相关知识的理解,积累实践经验。关于题目回顾与数据初探,可参考:天池离线赛 - 移动推荐算法(一):题目与数据解析,本文讨论如何基于模型来进行预测,测试的模型包括逻辑回归(LR)、随机森林(RF)、梯度迭代提升树(GBDT)。
基于模型的预测
(注:这里的实现基于 python 的 pandas、sklearn 等工具包。相关程序可参考My GitHub - model-based predication)
面向模型的数据预处理
经过天池离线赛 - 移动推荐算法(三):特征构建之后,在对特征数据样本套用模型进行分类预测之前,还需要根据具体所采用的模型对数据进行二次预处理,下面讨论其中重要的几点:
正负样本失衡问题
经过特征构建所得的数据集正负样本比例约为 1:1200,数据严重失衡,易导致模型训练失效。在这里,我们可通过下采样和基于 f1_score 的评价标准来应对此问题。
若考虑对训练集中的负样本进行下采样。为避免随机采样的特征空间覆盖性不足,先对负样本进行k-means聚类(参考Sergey Feldman所提方法(2)),然后在每个聚类上采用subsample来获得全面的负样本采样,最后与正样本组成较为平衡的训练集。
相关程序参考这里:基于k-means数据预处理 - python sklearn。
缺失值问题
在所构建的特征中,一些特征存在缺失值(如xx_diff_hours),这里,采用移除缺失值特征的数据集进行LR模型的训练,采用将缺失值赋值为-1的训练集进行RF/GBDT模型的训练。
归一化问题
在进行k-means和LR时,需要对不同度量尺度的特征进行归一化处理,这里我们采用
sklearn.preprocessing.StandardScaler()实现。
逻辑回归
逻辑回归(logistic regression,简称LR)是一种线性回归模型,另一种贴切的名称是“对数几率回归”,该模型采用对数几率函数逼近预测结果。这里采用sklearn.linear_model.LogisticRegression来训练模型。
由于LR模型对正负样本平衡十分敏感,所以在k-means的基础上采用下采样,通过参数调节选取最优的正负样本比(N/P_ratio),下图是LR训练时的 f1_score 随
N/P_ratio 变化示意图:
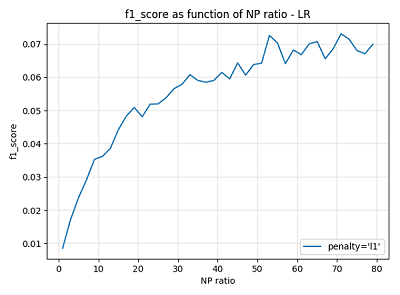
从图中看出,由于采用的是 f1 值进行评价,LR 模型在一定的 N/P_ratio 下的结果好一些,下面分别取 N/P_ratio = 35 和 N/P_ratio = 55,以预测的Sigmoid函数阈值参数 cut_off 为变量,观察模型在验证集上的表现:
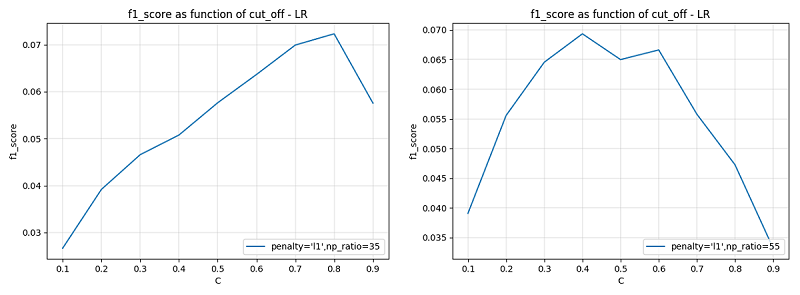
由上图看出,当 N/P_ratio 取值不同时,cut_off 的最优取值也不同,当 N/P_ratio 较小时,正例的特征空间相对较大,故而 cut_off 取值需要大一些,以压缩正样本预测空间,减小偏差;反之 cut_off 取值小一些。
将两种 [N/P_ratio, cut_off] 参数下的模型预测结果上传,评分如下所示:
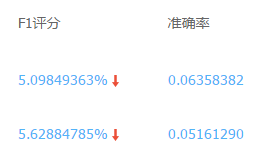
可见,结果不令人满意(比前面基于规则的预测效果要差)。在过程中我们发现,由于数据随机性、非线性等因素,采用 LR 这样的线性模型许难以实现更好的效果,所以重新考虑采用RF、GBDT等集成模型来实现。
随机森林
随机森林(Random Forest,简称RF)是一种基于决策树基模型的集成学习方法,其核心思想是通过特征采样来降低训练方差,提高集成泛化能力。这里我们采用sklearn.ensemble.RandomForestClassifier来随机森林的训练与预测任务。
在RF(或GBDT)的训练过程中,参数调节(parameter tuning)十分重要,一般地,将集成学习模型的参数分为两大类:过程参数和基学习器参数,一般地,先调试过程参数(如RF的基学习器个数n_estimators等),然后再调试基学习器参数(如决策树的最大深度max_depth等)。
下面讨论几个重要参数:
N/P_ratio(负正样本比例)
其实对于随机森林模型和下面的GBDT模型来说。其基学习器(决策树)采用“entropy”、“gini“等作为建树依据,对不同类别的划分具有强制作用。这类的模型对于类别失衡不敏感。但是过量冗余的负样本会严重加大训练消耗,所以也可以考虑在不影响模型训练的前提下对数据进行采样。
n_estimators(森林规模)
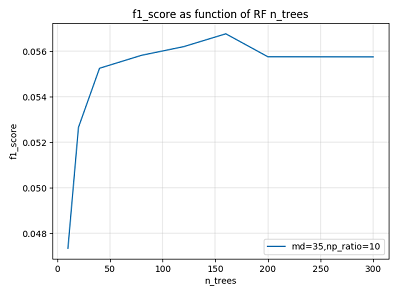
n_estimators 代表随机森林中基学习器(决策树)的个数,对应着“森林”的大小。一般地,森林规模越大,集成的方差越小,模型泛化能力越强,但规模越大导致计算开销越大,所以在保证泛化能力前提下取较合适的 n_estimators 值即可。
下图示是在某次参数调节中验证集 f1_score 随 n_estimators 的变化曲线,可以看到当 n_estimators 达到一定大小以后,继续增大无助于模型性能的提升。
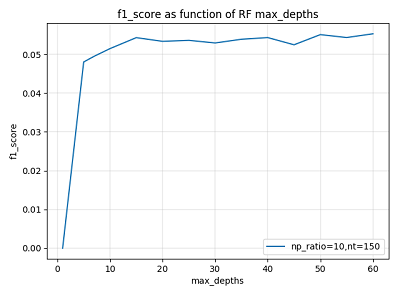
max_depth(树深度)
max_depth 属于基学习器参数,它控制着每个决策树的深度,一般来说,决策树越深,模型拟合的偏差越小,但同时拟合的开销也越大。一般地,需要保证足够的树深度,但也不宜过大。
下图示为某次参数调节过程中验证集 f1_score 随 max_depth 的变化曲线,可以看到当 max_depth 达到一定大小以后,继续增大无助于模型性能的提升。
min_samples_split(划分样本数)/min_samples_leaf(叶最小样本数)
这两个参数控制着分支粒度,防止着过拟合,效果相似。在RF中单个基学习器关注偏差,其叶节点粒度应该很小,所以这两个参数应设置得比较小。
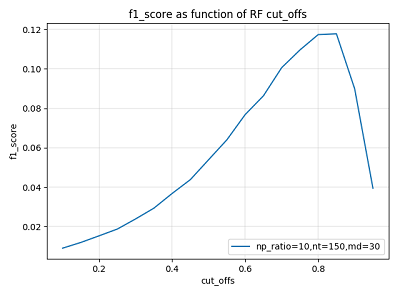
cut_off(预测概率阈值)
模型在对样本进行二分类预测时,首先得出的是样本所属类别的概率,然后通过阈值(如取cut_off = 0.5)划分得出结果。比如说:大于阈值判为正例,小于阈值的判为反例。该阈值反应了我们对于预测把握的估计,阈值越大的,要求的预测似然越大,对应的预测类别特征空间响应的收缩。
下图示为某次参数调节过程中验证集 f1_score 随 cut_off 的变化曲线,可以看到,此时的阈值应取大一些。
此外,还有许多的参数需要在模型训练时予以考虑。总的来说,参数调节是为了找到最适合于当前数据分布下的模型,由于参数众多,要找到这样一个全局最优的参数组合在实践中往往做不到,一个合理的方法是采用贪心的思路,先过程参数再基学习器参数,粗调与细调相结合,争取找到局部最优的参数组合,多次迭代此过程,使得局部最优的参数组合满足任务要求。
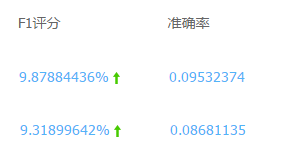
下面是两套参数组合下的预测结果评分,可以看到,基于此随机森林模型的预测结果明显优于之前的结果:
GBDT
GBDT(梯度迭代决策树)是一种基于决策回归树的Boosting模型,其核心思想是将提升过程建立在对“之前残差的负梯度表示”的回归拟合上,通过不断的迭代实现降低偏差的目的。这里我们采用sklearn.ensemble.GradientBoostingClassifier来实现GBDT分类器。
同随机森林一样,GBDT在训练时也需要进行大量的参数调节工作,以期获得适合于当前数据任务的模型。这里依然将GBDT的参数分为过程参数和基学习器参数两类,首先调节过程参数(学习率、基学习器个数等),然后调节基学习器参数(树深度、叶子分裂样本数等),推荐采用启发贪心式的参数调节方法,反复调节以期得到较好的参数组合。GBDT具体的调参对象与随机森林类似,但要注意二者集成本质的区别,下面是对一些重要参数的讨论:
N/P_ratio(负正样本比例)
和随机森林一样。考虑到过量冗余的负样本会严重加大训练消耗,考虑在不影响样本信息充分性的前提下对数据进行采样。
learning_rate(学习率)/n_estimators(基学习器数目)
这里,learning_rate 和 n_estimators 分别控制迭代的步长和最大迭代次数,所以,这两个参数应当一起调试,寻找最优的组合。GBDT设置大量基学习器的目的是为了集成来降低偏差,所以 n_estimators 一般会设置得大一些。
下图示为某次参数调节过程中验证集 f1_score 在不同 learning_rate 取值下随 n_estimators 的变化曲线。从图中可以看出,过大学习率导致拟合效果很差甚至出现发散,过小的学习率导致拟合太慢。图中学习率
lr=0.01的曲线总体上表现最好;另外我们可以看出,当迭代达到一定次数时,继续迭代对模型提升效果不大,据此可选择出一个合适的n_estimators取值。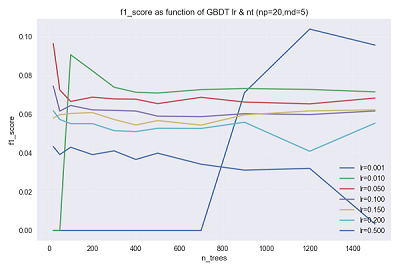
max_depth(树深度)
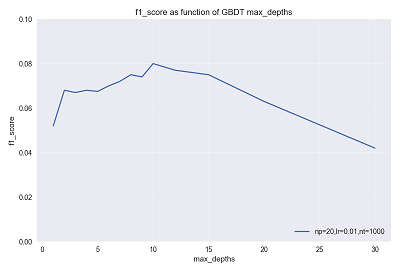
对于GBDT模型来说,其每个基学习器是一个弱学习器,决策树的深度一般设置得比较小,以此来降低方差,之后在经过残差逼近迭代来降低偏差,从而形成强学习器。所以不同于随机森林模型,这里的 max_depth 参数值应设置得比较小,
下图示为某次参数调节过程中验证集 f1_score 随 max_depth 的变化曲线。
min_samples_split(划分样本数)/min_samples_leaf(叶最小样本数)
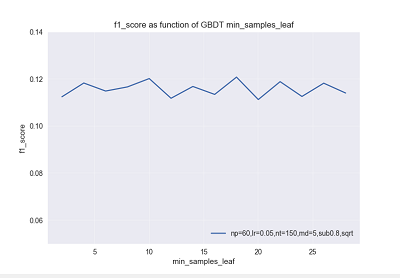
在GBDT中,单个基学习器侧重于降低方差,其叶节点粒度应该比较粗,所以这两个参数应设置得较大,但同时要考虑到数据失衡的情况,所以又不能设置得过大。
下图示为某次参数调节过程中验证集 f1_score 随 min_samples_leaf 的变化曲线。
cut_off(预测概率阈值)
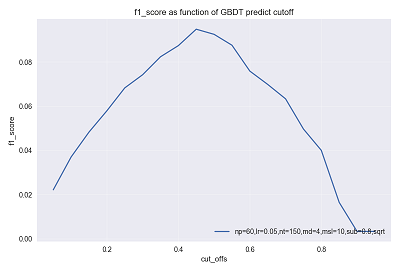
同随机森林中该项参数一致,cut_off 控制着我们对结果的置信程度。下图示为某次参数调节过程中验证集 f1_score 随 cut_off 的变化曲线,可以看出,当前参数设定下的训练器,取 cut_off ~ [0.4,0.6]比较合适,(p.s.cut_off分布较对称且矮胖得出来的结果比较稳定)。
除了上述参数之外,在一般调参的过程中还需要考虑的参数有:参考随机森林引入特征随机性的参数 max_features ,控制叶节点分裂粒度的参数 min_samples_split、min_samples_leaf 等。
下面是两套参数组合下的预测结果评分,可以看到,基于此GBDT模型的预测结果:
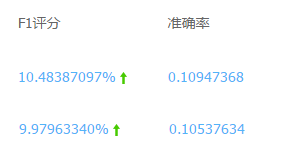
(p.s.借助GBDT的强大力量,终于有一次rank到了第2名….2/200)
结果总结
1. 过程回顾
任务被确立为基于模型的二分类,总体任务明确为是:分类模型套用 + 参数调节。
采用最简单的逻辑斯蒂回归(LR)进行了训练与预测,效果很差,进一步验证了数据随机性强、非线性的问题。
采用两种主流的集成学习方法随机森林(RF)和梯度提升树(GBDT)进行了训练与预测,效果提升明显,说明这种树集成的模型对工程实践中的随机性、非线性强,特征规约困难的数据适应性好。
2. 关于参数调节
在采用集成学习模型RF和GBDT时,参数优化对模型效果的提升十分明显,但是最优参数的获取往往是一个NP难题,故而采用启发式的贪婪搜索是一个相对好的选择。
对于集成模型,我们将其参数分为过程参数和基学习器参数两种,根据其对模型性能影响大小的经验判断来依次对其进行优化,不断的迭代往复进行直到获得一个满足要求的参数组合(一般是局部最优)。注意在整个过程中对拟合程度的把握,防止欠拟合/过拟合,拟合程度可根据训练过程中的训练损失(Train loss)、袋外估计(OOB),验证过程中的f1分数变化曲线等信息结合经验判断。
3. 其他
考虑到模型训练的效率以及对数据信息的学习能力,下一步拟采用XGBoost以期更好地实现当前任务。
参考资料
下面列出本文涉及的重要参考来源:
- 基础知识 - GBDT:GBDT:梯度提升决策树
- 实践技能 - 数据不平衡问题:在分类中如何处理训练集中不平衡问题
- 实践技能 - 数据不平衡问题:七招教你处理非平衡数据
- 实践技能 - 参数调节_RF:Tuning the parameters of your Random Forest model
- 实践技能 - 参数调节_GBDT:Complete Guide to Parameter Tuning in Gradient Boosting (GBM) in Python
- 编程实现 - sklearn集成学习主页:sklearn.ensemble
- 编程实现 - sklearn分类示例集合:Classifier comparison
- 编程实现 - sklearn:使用sklearn进行集成学习
- 赛题相关 - 阿里移动推荐算法思路解析
- 赛题相关 - 阿里巴巴移动推荐挑战赛FAQ